تفاوت Uptime Monitoring با Observability: کی باید از کدام استفاده کرد؟
در دنیای دیجیتال امروز، جایی که سایتها و سرورها قلب تپندهی کسبوکارها هستن، هیچ چیز بدتر از این نیست که کاربرانتون با صفحهی خطا روبرو بشن یا سرورها بدون دلیل خاصی کند بشن. انتخاب ابزار مناسب میتونه تفاوت بین یک downtime فاجعهبار و یک سیستم پایدار رو رقم بزنه. اما با وجود گزینههای زیادی مثل Uptime Monitoring و Observability، کدومشون واقعاً به دردتون میخوره؟
در ادامه میخوام عمیقتر به تفاوت Uptime Monitoring با Observability بپردازم. این دو مفهوم اغلب با هم اشتباه گرفته میشن، چون هر دو به نوعی به نظارت بر سیستمها مربوطن، اما در عمق و کاربردشون، فاصلهی زیادی دارن. اگر صاحب یک سایت ساده هستین یا یک سیستم پیچیدهی ابری رو مدیریت میکنین، فهمیدن این تفاوت Uptime Monitoring با Observability میتونه بهتون کمک کنه تا منابع رو درست تخصیص بدین و از مشکلات پیشگیری کنین. بیایم قدم به قدم پیش بریم و ببینیم هر کدوم چی هستن، چطور کار میکنن و کی باید سراغ کدوم بریم.
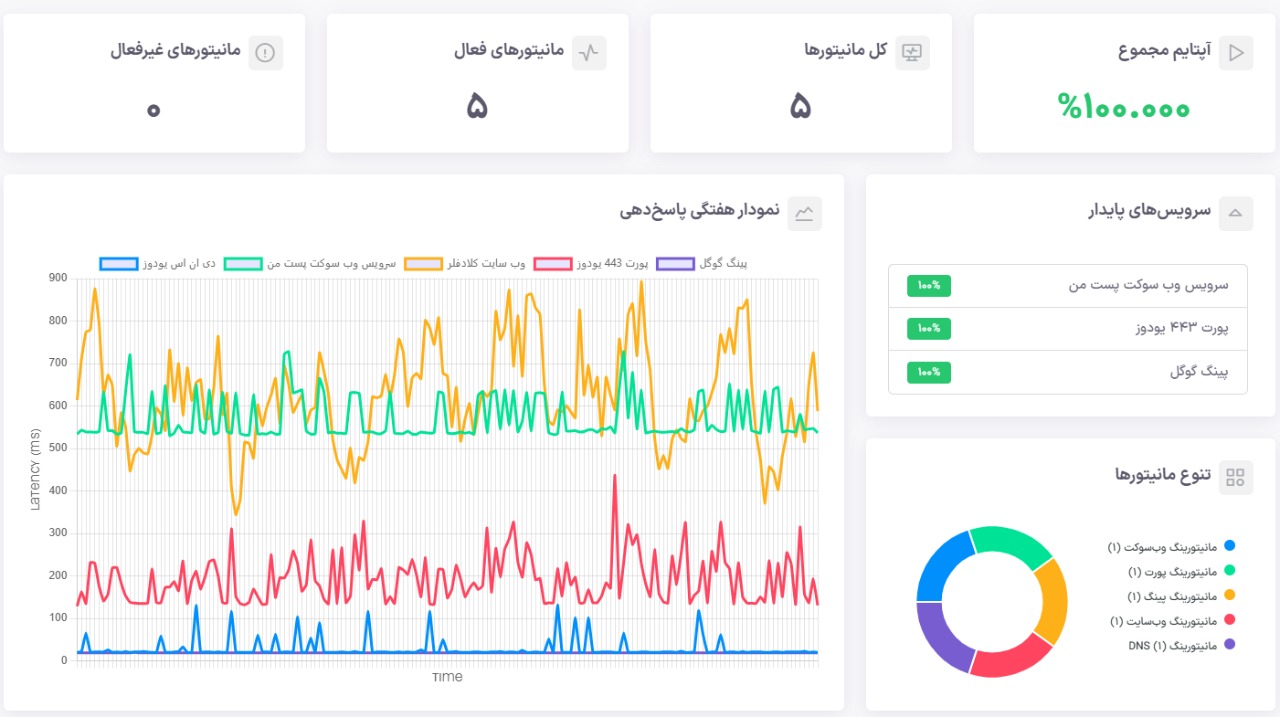
Uptime Monitoring چیه و چرا مهمه؟
بیایم اول با Uptime Monitoring شروع کنیم، چون این یکی از قدیمیترین و سادهترین روشهای نظارت بر سایت و سروره. به زبان ساده، Uptime Monitoring یعنی چک کردن اینکه سایت یا سرورتون “زنده” هست یا نه. تصور کنین یک ربات هر چند دقیقه یک بار به آدرس سایتتون سر بزنه و ببینه آیا صفحه لود میشه یا نه. اگر لود نشد، بلافاصله آلارم میده – مثلاً با ایمیل یا SMS بهتون هشدار میده.
این روش بر پایهی متریکهای پایهای مثل uptime (درصد زمانی که سایت در دسترسه) و response time (زمان پاسخدهی) کار میکنه. مثلاً اگر uptime سایتتون زیر 99.9% بره، یعنی هر ماه ممکنه تا 43 دقیقه downtime داشته باشین، که برای یک فروشگاه آنلاین میتونه ضرر مالی سنگین به همراه داشته باشه. ابزارهایی مثل UptimeRobot یا Pingdom دقیقاً برای همین طراحی شدن: ساده، ارزان و مؤثر برای سایتهای کوچک تا متوسط.
حالا چرا هنوز هم Uptime Monitoring یکی از پرکاربردترین روشهاست؟ چون ساده و کاربردیه. فرض کنید یک فروشگاه آنلاین یا حتی یک وبلاگ شخصی دارید؛ اولین چیزی که براتون مهمه اینه که مطمئن بشید سایت همیشه در دسترس کاربرهاست. ابزارهای Uptime دقیقاً همین کار رو میکنن.
در یودوز ما همیشه توصیه میکنیم حتی در ابتداییترین مراحل راهاندازی یک پروژه، از مانیتورینگ آپتایم استفاده کنید. چرا؟ چون بدون نیاز به پیچیدگیهای فنی، خیال شما رو راحت میکنه که پایهی نظارت روی سایت محکم بنا شده. اما باید بدونید که این روش محدودیت هم داره: Uptime Monitoring فقط به شما اطلاع میده «سایت بالا هست یا نه»، ولی علت اصلی رو مشخص نمیکنه. مثلاً اگر وبسایت شما down بشه، هشدار دریافت میکنید، اما نمیفهمید مشکل از زیرساخت اینترنت یا از کدنویسی سایت بوده، یا فشار ترافیک بالا باعثش شده.
Observability: نگاهی عمیقتر به درون سیستم
حالا برسیم به Observability، که مثل یک رادیولوژیست حرفهای عمل میکنه – فقط نمیگه استخونتون شکسته، بلکه نشون میده دقیقاً کجا و چرا. Observability یک رویکرد جامعه که از سه ستون اصلی تشکیل شده: logs (ثبت وقایع)، metrics(اندازهگیریها مثل CPU و memory) و traces (ردیابی درخواستها در سیستمهای توزیعشده).
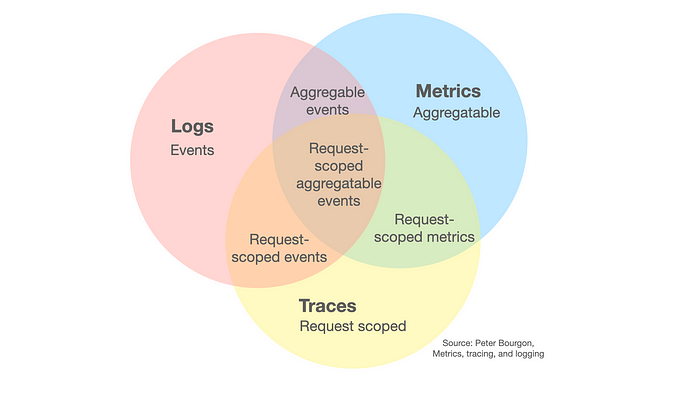
تفاوت کلیدی Observability با نظارتهای سنتی اینه که proactive عمل میکنه. یعنی به جای منتظر ماندن برای شکست، الگوهای مشکوک رو زودتر شناسایی میکنه. مثلاً در یک اپلیکیشن میکروسرویس، Observability میتونه نشون بده که یک API کند شده چون دیتابیس overload هست، در حالی که Uptime Monitoring فقط میگه “سایت کُنده”. ابزارهایی مثل Datadog، New Relic یا Grafana برای این کار عالیان، چون دادهها رو جمعآوری میکنن، همبستگی میدن و داشبوردهای هوشمند میسازن.
در عمل، Observability برای تیمهای DevOps یک نجاتدهندهست. تصور کنین ما یک پروژهی ابری رو مدیریت میکنیم؛ با Observability، میتونیم ببینیم چطور یک تغییر کوچک در کد، روی کل زنجیرهی سرویسها تأثیر گذاشته. این روش نه تنها downtime رو کاهش میده، بلکه MTTR (زمان میانگین حل مسئله) رو هم به شدت کم میکنه – گاهی تا 50%!
تفاوت Uptime Monitoring با Observability: جدول مقایسه
برای اینکه تفاوت Uptime Monitoring با Observability رو بهتر بفهمیم، بیاید یک جدول ساده بسازیم. این جدول بر اساس تجربیات واقعی از پروژههای یودوز (Yodevs) تهیه شده:
| ویژگی | Uptime Monitoring | Observability |
|---|---|---|
| تمرکز اصلی | در دسترس بودن (uptime) و پاسخدهی ساده | درک عمیق سیستم (چرا و چطور) |
| دادههای استفادهشده | پینگها و چکهای HTTP | Logs, Metrics, Traces |
| رویکرد | Reactive (واکنشی) | Proactive (پیشگیرانه) |
| مناسب برای | سایتهای ساده، SMBها | سیستمهای پیچیده، میکروسرویسها |
| هزینه | پایین (اغلب رایگان) | بالاتر (به خاطر تحلیل پیشرفته) |
| مزایا | سریع راهاندازی، آلارم فوری | root cause analysis، بهینهسازی مداوم |
| معایب | سطحی، بدون جزئیات علت | پیچیدهتر، نیاز به expertise |
این جدول نشون میده که تفاوت Uptime Monitoring با Observability بیشتر در عمقه؛ یکی مثل نگهبان درِ ورودیه، دیگری مثل کنترلکنندهی کل کارخانه.
کی باید از Observability استفاده کرد؟
Observability وقتی حیاتی میشه که سیستم شما از حالت ساده خارج شده و به یک اکوسیستم پیچیده با چندین سرویس و وابستگی تبدیل بشه. در این شرایط، صرفاً دانستن اینکه “سرویس داونه” کافی نیست؛ شما باید بدونید چرا این اتفاق افتاده.
🔹 زمانهایی که Observability اهمیت داره:
-
سیستمهای توزیعشده و ابری: وقتی اپلیکیشنتون روی Kubernetes یا AWS یا چندین میکروسرویس اجرا میشه.
-
نیاز به Debug و Trace کردن درخواستها: مخصوصاً توی تیمهای DevOps که باید مسیر یک درخواست از ابتدا تا انتها قابل ردیابی باشه.
-
رشد سریع محصول: وقتی خطاها و downtime زیاد میشن و علت مشخص نیست.
🔹 چرا ابزارهای Observability مهم هستن؟
ابزارهای Observability فقط uptime رو بررسی نمیکنن، بلکه دادههای عمیقی از سیستم جمعآوری میکنن، مثل:
-
Logs (لاگها): ثبت جزئیات رخدادها و خطاها.
-
Metrics (متریکها): دادههای عددی مثل میزان استفاده از CPU، RAM، I/O دیسک و ترافیک شبکه.
-
Traces (تریسها): ردیابی جریان درخواستها بین سرویسهای مختلف برای پیدا کردن گلوگاهها.
در یودوز، برای مشتریان اولیه که یک وبسایت وردپرسی دارن، همیشه Uptime Monitoring رو پیشنهاد میکنیم. چون 80% مشکلاتشون با این حل میشه و downtime رو به زیر 1% میرسونه. اما اگر ترافیک بالاست یا SLA (توافقنامه سطح سرویس) سختی دارین، این تنها کافی نیست.
کی باید از Observability استفاده کرد؟
از طرف دیگه، Observability برای وقتیه که سیستمتون پیچیده شده. نشانهها:
- سیستمهای توزیعشده: مثل اپهای ابری با Kubernetes یا AWS.
- تیم DevOps: جایی که نیاز به trace کردن درخواستها دارین.
- رشد سریع: اگر downtimeها دارن افزایش پیدا میکنن و علتشون نامشخصه.
مثلاً در یک پروژهی e-commerce، با پیادهسازی Observability، امکانش هست که یک bottleneck در دیتابیس پیدا کنیم که Uptime Monitoring اصلاً متوجهش نشده باشه. نتیجه؟ uptime از 98% به 99.99% میرسه و فروش بیش از 20% افزایش پیدا کنه. اگر کاربراتون تجربهی بدی دارن – مثل لود کند بدون down بودن سایت – وقتشه سراغ Observability برین.
مزایای ترکیب Uptime Monitoring و Observability
چرا یکی رو انتخاب کنیم وقتی میتونیم هر دو رو داشته باشیم؟ تفاوت Uptime Monitoring با Observability به این معنی نیست که یکی رو دور بندازیم؛ برعکس، ترکیبشون مثل یک تیم کامله. Uptime Monitoring آلارمهای فوری میده، Observability علت رو پیدا میکنه.
در یودوز، ما یک پکیج ترکیبی پیشنهاد میدیم: شروع با uptime برای پایه، بعد اضافه کردن observability برای عمق. مزایاش؟
- کاهش MTTR (زمان میانگین حل مسئله) : از ساعتها به دقیقهها.
- بهینهسازی هزینه: جلوگیری از over-provisioning منابع.
- بهبود UX: کاربرا کمتر frustrated میشن.
طبق گزارش New Relic، شرکتهایی که هر دو رو استفاده میکنن، 40% uptime بهتری دارن.
ابزارهای پیشنهادی برای مانیتورینگ سایت و سرور
انتخاب ابزار بستگی به نیاز داره، اما اینجا چند تا رو بر اساس تفاوت Uptime Monitoring با Observability لیست میکنم:
ابزارهای Uptime Monitoring
- Yodevs: پلن رایگان بینظیر برای مبتدی ها! 5 مانیتور فعال + فاصله چک 3 دقیقهای + 2 سیستم یکپارچهسازی فعال
- Pingdom: با گزارشهای دقیق، مناسب SMBها.
- UptimeRobot: رایگان، چک هر 5 دقیقه، عالی برای مبتدیها.
ابزارهای Observability
- Datadog: همهچیز رو track میکنه، ادغام آسان با کلود.
- Grafana + Loki:پروژه open-source، برای تیمهای فنی.

نتیجهگیری: انتخاب درست بر اساس نیازتون
در نهایت، تفاوت Uptime Monitoring با Observability در اینه که اولی نگهبانه، دومی دانشمند. اگر سایتتون سادهست، با Uptime Monitoring شروع کنین – سریع و مؤثره. اما اگر سیستمتون داره رشد میکنه و مشکلات نامرئی دارین، Observability رو فراموش نکنین؛ این کار نه تنها downtime رو کم میکنه، بلکه کسبوکارتون رو resilient تر میکنه.
اگر سؤالی دارین یا میخواین در مورد پیادهسازی در پروژهتون حرف بزنیم، کامنت بذارین یا با تیم ما تماس بگیرین. ما اینجا هستیم تا سایت و سرورهاتون رو دائم بررسی کنیم تا قبل از مشتریانتون متوجه خطاها بشید. uptime مهمه و observability آیندهست!